2024. 3. 21. 01:48ㆍAI/기계학습
- 교차검증이란?
데이터를 여러 번 나누고, 매번 서로 다른 부분 집합을 사용하여 모델을 반복적으로 훈련하고 나머지 데이터를 사용하여 모델을 테스트합니다.
훈련데이터가 많지 않을 때 모델이 훈련 데이터에 과적합(overfitting)되는 것을 방지하고, 일반화 성능을 측정하는데 유용합니다.
- 교차검증을 수행하는 함수
1. cross_val_score
- k-fold 교차검증을 사용하고, k는 분석가 지정할 수 있다.
- 이 함수는 모델, 입력 데이터, 타겟 레이블과 함께 교차 검증 방법(예: KFold, StratifiedKFold)을 인자로 받아, 각 폴드에 대한 성능 점수를 반환다.
- 클래스의 불균형 상관없이 알아서 잘 확인하고 편하게 사용할 수 있다.
- cross_val_score 주요 매개변수, cross_val_score(모델, x, y, cv= , scoring=?)
- estimator : 분류 모형 또는 회귀 모형 객체 (DTC, DTR 등등)
- X : 피쳐 데이터 세트
- y : 레이블 데이터 세트
- scoring : 예측 성능 평가 지표 (accuracy : 분류, r-squre: 회귀 등)
- cv : 교차 검증 폴드 수
- n_jobs: 사용할 CPU 코어 수 (-1인 경우 최대한 많이 사용)
2. cross_validate, cross_validate(모델, x, y, cv=?, scroing=?, return_train_score=True)
- 여러가지 추가 정보들을 확인할 수 있다. 테스트 훈련시간이나, 테스트 시간 등, 정밀도 재현율, 다른 평가지표 한 번에 볼 수 있음
- 기능적으로 좀 더 세부적으로 볼 수 있다
- 이중분류의 평가지표
이중분류의 평가지표는 다음의 예시처럼 통상적으로 알고 있는 방법이다.
Accuracy : (TP+TN)/(TP+FN+FP+TN)
Sensitivity : TP/(TP+FN)
Precision : TP/(TP+FP)
cf) '이중분류'란? Model이 Training Data로 가중치와 편향을 학습하고 새롭게 들어온 Sample이 Class 2개 중에 어느 곳에 속하는지 알려주는 것. e.g. 사진을 한 장 주었을 때(새로운 Sample) 이 사진이 고양이인지(class1) 강아지인지(class2) 분류해라.
- 다중분류의 평가지표
다중분류는 이진분류의 평가지표 계산 방법과 다르다.
e.g. iris dataset은 다중분류가 된다. 이진분류로 생각하는 평가지표에서 nan이 결과로 나온다.
- 다중분류의 precision, recall, f1스코어 등 평가지표 계산 방법
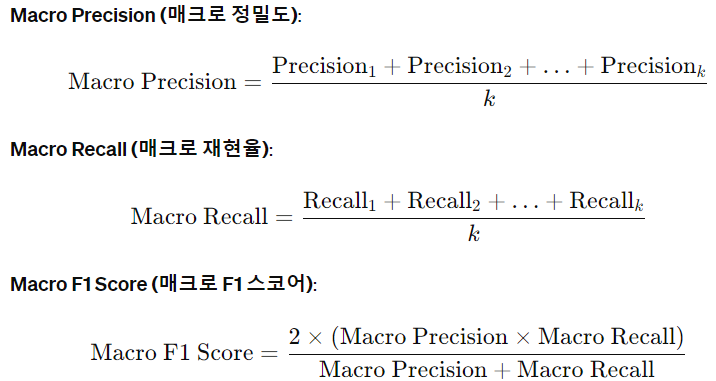
1. Macro 평균 (Macro Average)
Macro 평균은 각 클래스의 precision, recall, F1 스코어를 각각 계산한 후, 이를 클래스의 수로 나눈 값의 평균을 구함
Macro 평균은 클래스의 크기와 상관없이 각 클래스에 대해 동일한 가중치를 부여
2. Micro 평균 (Micro Average)
Micro 평균은 모든 클래스의 TP, FP, FN 값을 합하여 전체적인 precision, recall, F1 스코어를 계산
Micro 평균은 각 샘플의 중요도에 따라 가중치를 부여

3. Weighted 평균 (Weighted Average)
Weighted 평균은 Macro 평균과 유사하지만, 클래스의 크기에 따라 가중 평균을 계산
Weighted 평균은 클래스의 크기에 따라 각 클래스에 가중치를 부여하여 계산
'AI > 기계학습' 카테고리의 다른 글
| K-최근접 이웃, K-Nearest Neighbors (K-NN) (0) | 2023.01.05 |
|---|---|
| 군집 (0) | 2022.11.28 |
| 차원축소(PCA) (0) | 2022.11.24 |
| 회귀분석(Regression Analysis) (0) | 2022.11.15 |
| Machine Learning1 - 정의와 종류 (0) | 2022.11.10 |