2022. 11. 15. 17:51ㆍAI/기계학습
회귀분석(Regression Analysis) 변수 간의 인과관계를 밝히기란 매우 어려운 문제다. 수학적 방법 이외에 다양한 외적 조건도 따져봐야 한다. 회귀분석은 이런 과정 중에 하나에 불과하다.
- 특정변수(독립변수)가 다른 변수(종속변수)에 어떤 영향을 미치는가를 분석한다. 즉, 인과관계를 분석한다.
- 독립, 종속변수는 등간 또는 비율척도 (연속형 데이터)로 구성되어야 한다.
- 독립변수 중에서 종속변수에 영향을 미치는 변수를 규명하고, 이들 변수들에 의해서 회귀방정식을 도출하여 회귀선을 추정한다. Y = Wx + b 회귀분석에서 Weight와 bias의 최적값을 찾는 것(최소제곱법 사용)이 좋은 회귀식을 만들 수 있는 조건이다.
- 회귀분석은 시간에 따라 변화하는 데이터나 어떤 영향, 가설적 실험, 인과 관계의 모델링 등의 통계적 예측에 이용될 수 있다.
- 회귀분석의 기본 가정 충족 조건으로 선형성, 잔차 정규성, 잔차 등분산성, 잔차 독립성, 다중 공선성 등이 있다.
# 방법2 : LinearRegression을 사용. model 만들어짐
from sklearn.linear_model import LinearRegression
model = LinearRegression()
fit_model = model.fit(xx, yy) # 이미 수집된 학습 데이터로 모형 추정 : 절편, 기울기 얻음(내부적으로 최소 제곱법)
print('기울기(slope, w) : ', fit_model.coef_) # coef 회귀계수, 기울기
print('절편(bias, b) : ', fit_model.intercept_) # y 절편
# 단순선형회귀 모델
# 기본적인 결정론적 선형회귀 방법 : 독립변수에 대해 대응하는 종속변수와 유사한 예측값을 출력하는 함수 f(x)를 찾는 작업이다.
import pandas as pd
df = pd.read_csv("../testdata/drinking_water.csv")
print(df.head(3))
print(df.corr())
import statsmodels.formula.api as smf
# 적절성이 만족도에 영향을 준다라는 가정하에 모델 생성
model = smf.ols(formula = '만족도 ~ 적절성', data=df).fit() # 모델의 파라미터가 성능을 결정한다
# R에서는 fit()이 내부적으로 처리된다
print(model.summary()) # 생성된 모델의 요약결과를 반환. 능력치를 확인.
# 잔차의 독립성 : Durbin-Watson: 2.185
# 왜도(꼬리Skew),첨도(Kurtosis완만,뾰족)
<회귀분석모형의 적절성을 위한 조건 확인 5개>
1) 정규성 : 독립변수들의 잔차항이 정규분포를 따라야 한다.
# Q-Q plot으로 확인
import scipy.stats
sr = scipy.stats.zscore(residual)
(x, y), _ = scipy.stats.probplot(sr)
sns.scatterplot(x, y)
plt.plot([-3,3], [-3,3], '--', color='grey')
plt.show() # 정규성을 만족하지 못함 : log를 취하는 등의 작업을 통해 정규분포를 따르도록 데이터 가공 작업 필요
# 정규성은 shapiro test로도 수치로 확인 가능
print('shapiro test : ',scipy.stats.shapiro(residual)) # < 0.05이므로 정규성 만족 못함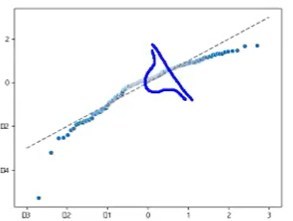
->Q-Q plot으로 확인했을때
양 끝이 정규분포를 벗어났기 때문에 정규성을 만족한다고 볼 수 없다.
2) 독립성 : 독립변수들 간의 값이 서로 관련성이 없어야 한다.
Durbin-Watson: 잔차의 독립성 만족여부 확인 가능하다.
2에 근사하면 자기상관이 없다. (0 <- 양의 상관 - 2독립성 - 음의 상관 -> 4)
summary()로 확인한 결과 2.081이므로 잔차의 독립성은 만족
3) 선형성 : 독립변수의 변화에 따라 종속변수도 변화하나 일정한 패턴을 가지면 좋지 않다.
# 예측값과 잔차가 비슷하게 유지되어야 함
sns.regplot(fitted, residual, lowess=True, line_kws={'color':'red'})
plt.plot([fitted.min(), fitted.max()], [0,0], '--')
plt.show() # 선형성을 만족하지 못함. 다항회귀를 추천

->예측값과 잔차가 비슷하게 유지되어야 하는데
그래프에서 비슷하지 않은 것을 확인했으므로
선형성을 만족하지 못함. 다항회귀를 추천
seaborn.regplot (파이썬에서 선형성을 확인할 수 있는 함수)
Parameters : lowess(부울, 선택 사항) -> If True, use statsmodels to estimate a nonparametric lowess model (locally weighted linear regression). Note that confidence intervals cannot currently be drawn for this kind of model.
비모수적 lowess 모델(로컬 가중 선형 회귀)을 추정하는 데 True사용한다.
출처 https://seaborn.pydata.org/generated/seaborn.regplot.html
4) 등분산성 : 독립변수들의 오차(잔차)의 분산은 일정해야 한다. 특정한 패턴 없이 고르게 분포되어야 한다.
sns.regplot(fitted, np.sqrt(np.abs(sr)), lowess=True, line_kws={'color':'red'})
plt.show() # 일정한 패턴의 곡선을 그리므로 등분산성을 만족하지 못함
-> 데이터들이 일정하지 않으므로 등분산성을 만족하지 못한다.
이상값 확인, 비선형인지 확인, 정규성을 확인한다. 만약에 정규성은 만족하나 등분산성을 만족하지 못하는 경우에는 가중회귀분석을 추천한다.
5) 다중공선성 : 독립변수들 간에 강한 상관관계로 인한 문제가 발생하지 않아야 한다.
VIF(분산팽창계수)를 사용해서 확인, VIF가 10이 넘으면 다중공선성 있다고 판단하며 5가 넘으면 주의할 필요가 있다.
from statsmodels.stats.outliers_influence import variance_inflation_factor
print(advdf.head(3)) # tv radio newspaper sales
# summary()의 결과에서 coef의 순서는 Intercept:0, tv:1, radio:2
print(variance_inflation_factor(advdf.values, 1)) # tv 12
print(variance_inflation_factor(advdf.values, 2)) # radio 3
vifdf = pd.DataFrame() # 다른방법으로도 확인가능
vifdf['vif_value'] = [variance_inflation_factor(advdf.values, i) for i in range(1, 3)]
print(vifdf)
Cf) Cook's distance - 극단값(이상치)을 나타내는 지표
from statsmodels.stats.outliers_influence import OLSInfluence
cd, _ = OLSInfluence(lm_mul).cooks_distance
print(cd.sort_values(ascending=False).head())
import statsmodels.api as sm
sm.graphics.influence_plot(lm_mul, criterion='cooks')
plt.show()
print(advdf.iloc[[130, 5, 35, 178, 126]]) #이상치 데이터로 의심됨으로 제거 권장'AI > 기계학습' 카테고리의 다른 글
| 교차검증(Cross-Validation) (0) | 2024.03.21 |
|---|---|
| K-최근접 이웃, K-Nearest Neighbors (K-NN) (0) | 2023.01.05 |
| 군집 (0) | 2022.11.28 |
| 차원축소(PCA) (0) | 2022.11.24 |
| Machine Learning1 - 정의와 종류 (0) | 2022.11.10 |