2023. 1. 5. 17:55ㆍAI/기계학습
지도 학습의 알고리즘 : K-최근접 이웃(K-nearest neighbor)
K-최근접 이웃(K-nearest neighbor)?
새로운 입력을 받았을 때 기존 클러스터에서 모든 데이터와 인스턴스(데이터와 데이터 사이 거리) 기반 거리를 측정한 후 가장 많은 속성을 가진 클러스터에 할당하는 분류 알고리즘
훈련 데이터를 충분히 확보할 수 있는 환경에서 사용
KNN 알고리즘(Knn 회귀, 분류, 이상치 탐지 등)
KNN 알고리즘의 파라미터
- n_neighbors : 이웃 수, k의 값, default는 5
- weights: 이웃의 가중치 결정방법
- 디폴트 'uniform' 동일한 가중치
- 'distance' 거리의 반비례 가중치
- 'callable' 사용자가 직접 정의한 함수를 사용할 수도 있다. 거리가 저장된 배열을 입력으로 받고 가중치가 저장된 배열을 반환하는 함수가 되어야 한다.
- metric : 거리측정방식
- 'euclidean'
- 'manhanttan'
- algorithm : 거리 기반으로 계산하는 데 사용하는 알고리즘을 결정
- 'auto' : 가장 적정한 것 골라서 데이터 차원,패턴에 따라서 자동을 탐색하는 것, 디폴트
- 'ball_tree' : 필요한 부분 빠르게 탐색하기 위한 방법, Ball-Tree 구조를 사용
- 'kd_tree' : 데이터 구조, 분할방식으로 차원 축소하면서 진행하는 방법, KD-Tree 구조를 사용
- 'brute' : 완전탐색방식 가장직관적인 방법, 데이터 크면 계산이 증가한다.
KNeighborsRegressor, KNeighborsClassifier
KNN은 주로 분류(Classification)와 회귀(Regression) 문제에 사용. 학습된 KNN 모델은 주어진 입력 데이터에 대해 가장 가까운 이웃들의 클래스 또는 값들을 기반으로 예측을 수행하는 지도 학습 알고리즘
KNeighborsRegressor
이 모델은 주어진 입력 데이터에 대해 K개의 가장 가까운 이웃들의 타겟 변수(레이블) 값의 평균을 사용하여 연속형 타겟 변수의 값을 예측
from sklearn.neighbors import KNeighborsRegressor
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import fetch_california_housing
from sklearn.neighbors import KNeighborsRegressor
from sklearn.model_selection import train_test_split, cross_val_score
import numpy as np
#가중치에 따른 실제 학습
import numpy as np
import matplotlib.pyplot as plt
from sklearn import neighbors
np.random.seed(0)
X = np.sort(5 * np.random.rand(40, 1), axis=0)
T = np.linspace(0, 5, 500)[:, np.newaxis]
y = np.sin(X).ravel()
# Add noise to targets
y[::5] += 1 * (0.5 - np.random.rand(8))
n_neighbors = 5
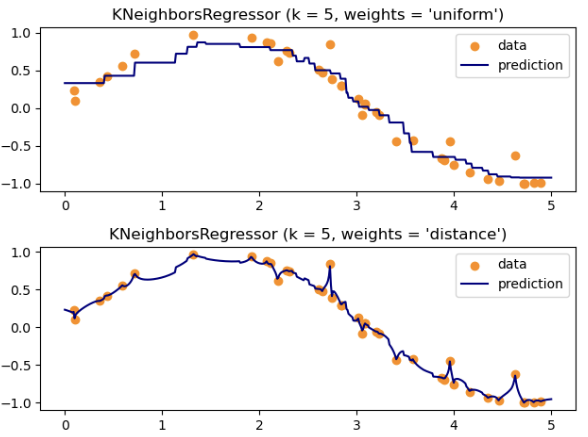
for i, weights in enumerate(["uniform", "distance"]):
knn = neighbors.KNeighborsRegressor(n_neighbors, weights=weights)
y_ = knn.fit(X, y).predict(T)
plt.subplot(2, 1, i + 1)
plt.scatter(X, y, color="darkorange", label="data")
plt.plot(T, y_, color="navy", label="prediction")
plt.axis("tight")
plt.legend()
plt.title("KNeighborsRegressor (k = %i, weights = '%s')" % (n_neighbors, weights))
plt.tight_layout()
plt.show()
KNeighborsClassifier
# KNeighborsClassifier
iris = load_iris()
X = iris.data
y = iris.target
# iris데이터로 분류 작업 진행
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.3, random_state=111)
# 간단한 그리드서치로 최적을 찾기
from sklearn.model_selection import GridSearchCV
# 하이퍼파라미터
param_grid = {'n_neighbors':range(1,20),'weights':['uniform','distance']}
#grid_search
grid_search = GridSearchCV(KNeighborsClassifier(), param_grid, cv=3, scoring='accuracy')
# 그리드서치 수행
grid_search.fit(X_train, y_train)
#최적의 하이퍼파라미터
print('최적의 하이퍼 파라미터:', grid_search.best_params_)
print('최적의 스코어:', grid_search.best_score_)
#최적의 하이퍼 파라미터: {'n_neighbors': 5, 'weights': 'uniform'}
#최적의 스토어: 0.980952380952381
NearestNeighbors 클래스
NearestNeighbors 클래스는 입력 데이터의 구조를 파악하고 데이터 간의 거리를 측정하는 데 사용되는 비지도 학습. 데이터 간의 유사성을 이해하거나 클러스터링(Clustering), 이상치 탐지(Outlier Detection) 등의 작업에 활용
from sklearn.neighbors import NearestNeighbors
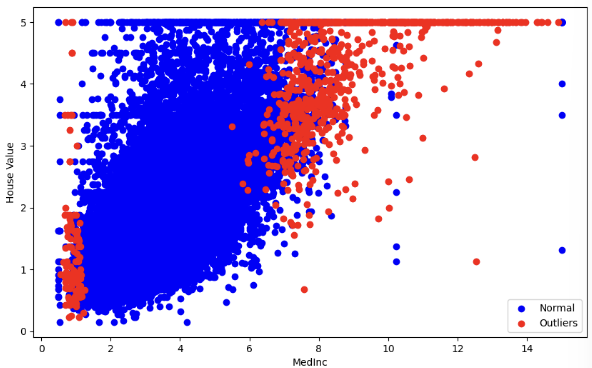
# 캘리포니아 데이터를 통해 이상치 탐지
cal = fetch_california_housing()
X= cal.data
y= cal.target
## MedInc 집값 컬럼 0번째 컬럼
X_MedInc = X[:,0].reshape(-1,1) # 집값 데이터만 추출
#Knn 모델로 이웃이 5개 거리 계산해서 이상치 탐지해보자
nbrn = NearestNeighbors(n_neighbors = 5, algorithm='ball_tree').fit(X_MedInc)
distance, indices = nbrn.kneighbors(X_MedInc)
# indices[i]는 X_MedInc의 i번째 데이터 포인트에 대한 가장 가까운 이웃들의 인덱스를 담은 배열
distance # distance[i]는 데이터셋 X_MedInc 내의 i번째 데이터 포인트와 그 데이터 포인트의 가장 가까운 이웃들 간의 거리를 담은 배열, n_neighbors 개수만큼, 거리가 가까운 순서대로 정렬
# [0. , 0. , 0. , 0. , 0. ] -> 데이터 전처리
# 거리기준으로 이상치 점수 계산해서
outlier_scores = distance[:,-1] # 모든 행에 대해 마지막 열의 값, 가장 먼 이웃까지의 거리
# 이상치 점수가 특정 임계값을 넘으면 이상치로 판단
# 상위 5% 이상치 간주하자!
thres = np.percentile(outlier_scores, 95)
is_outlier = outlier_scores > thres
## outlier 시각화 하기
plt.figure(figsize=(10,6))
plt.scatter(X_MedInc[~is_outlier], y[~is_outlier], color='blue', label= 'Normal') # ~is_outlier is_outlier가 False
plt.scatter(X_MedInc[is_outlier], y[is_outlier], color='red', label= 'Outliers')
plt.xlabel('MedInc')
plt.ylabel('House Value')
plt.legend()
'AI > 기계학습' 카테고리의 다른 글
| 교차검증(Cross-Validation) (0) | 2024.03.21 |
|---|---|
| 군집 (0) | 2022.11.28 |
| 차원축소(PCA) (0) | 2022.11.24 |
| 회귀분석(Regression Analysis) (0) | 2022.11.15 |
| Machine Learning1 - 정의와 종류 (0) | 2022.11.10 |